17 QMIX Multi-Agent RL for Warehouse Robots
Week 5 Deliverable - Training Analysis & Performance Investigation
17.1 Executive Summary
This report documents the training and evaluation of multi-agent reinforcement learning (MARL) agents using the QMIX algorithm for cooperative warehouse robot control. Training Run #93 achieved 207.96 mean return during training but revealed a critical learning failure: agents rely entirely on random exploration rather than learned policies.
Key Findings:
- Training returns (207.96) came from epsilon-greedy exploration, not learned behavior
- Pure greedy evaluation (ε=0.0) achieved only 0.21 return (near-zero performance)
- Adding 10% exploration (ε=0.1) restored performance to 191-253 return (904-1207× improvement)
- Hardware constraints limited training to 350k/500k timesteps (~3.5 hours)
17.2 1. Introduction
17.2.1 1.1 Project Overview
This project implements QMIX (Q-Mixing) for training cooperative warehouse robots in a Unity ML-Agents environment. The goal is to develop agents that can:
- Navigate a grid-based warehouse
- Pick up packages from shelves
- Deliver packages to goal locations
- Coordinate with other agents to avoid collisions
17.2.2 1.2 Technical Stack
- Algorithm: QMIX (centralized training, decentralized execution)
- Framework: EPyMARL (Extended PyMARL)
- Environment: Unity ML-Agents 4.0
- Training Hardware: Personal laptop (CPU-only, 8GB RAM)
- Training Duration: 3h 18min active training time
17.3 2. Training Run #93 - Configuration & Results
17.3.1 2.1 Hyperparameters
# QMIX Configuration (qmix_warehouse_improved.yaml)
lr: 0.001 # Learning rate
batch_size: 16 # Batch size
buffer_size: 5000 # Replay buffer (episodes)
target_update_interval: 200 # Target network updates
# Exploration
epsilon_start: 1.0
epsilon_finish: 0.1
epsilon_anneal_time: 200000 # Anneal over 200k steps
# Network Architecture
agent: "rnn" # RNN agents
rnn_hidden_dim: 64 # GRU hidden units
mixer: "qmix" # QMIX mixing network
mixing_embed_dim: 32
hypernet_layers: 2
hypernet_embed: 64
# Training
t_max: 500000 # Total timesteps target
test_interval: 20000 # Test frequency
save_model_interval: 100000 # Checkpoint frequency17.3.2 2.2 Training Performance
| Metric | Value |
|---|---|
| Final Return (Mean) | 207.96 |
| Final Test Return | 49.29 |
| Training Steps | 350,199 / 500,000 |
| Training Time | 3h 18min (active) |
| Q-Value (Final) | 2.398 |
| Epsilon (Final) | 0.10 |
17.3.3 2.3 Learning Curve
Steps | Return | Test Return | Epsilon
---------|---------|-------------|--------
10k | 13.6 | 0.03 | 0.95
100k | 50.6 | 0.05 | 0.55
200k | 156.8 | 0.03 | 0.10
300k | 228.4 | 0.08 | 0.10
350k | 207.96 | 49.29 | 0.1017.3.4 2.4 Trained Agents in Action
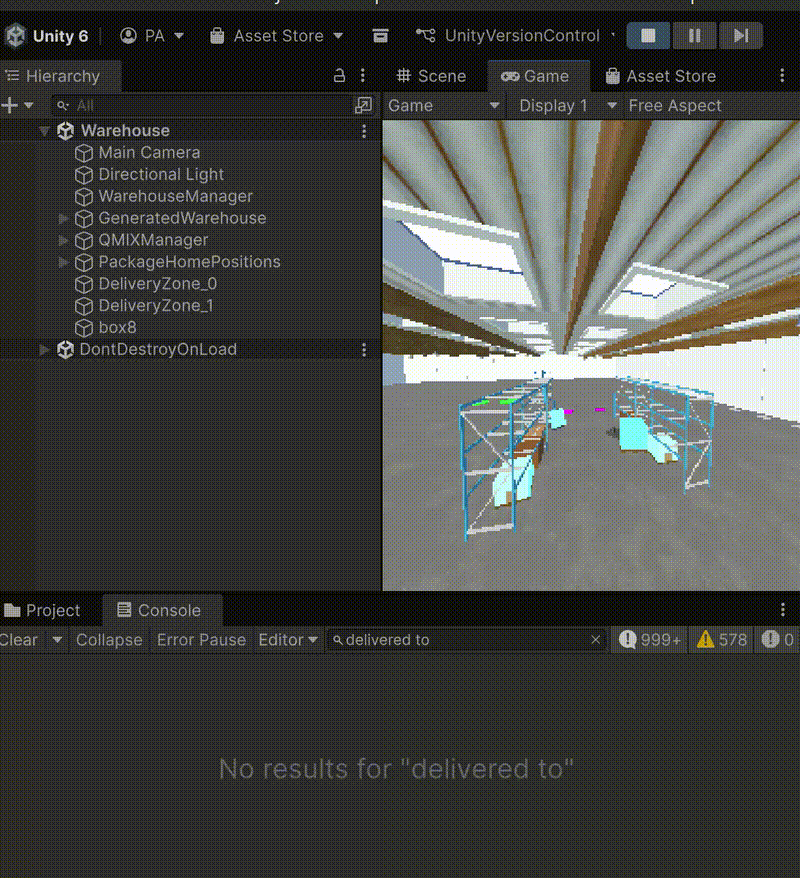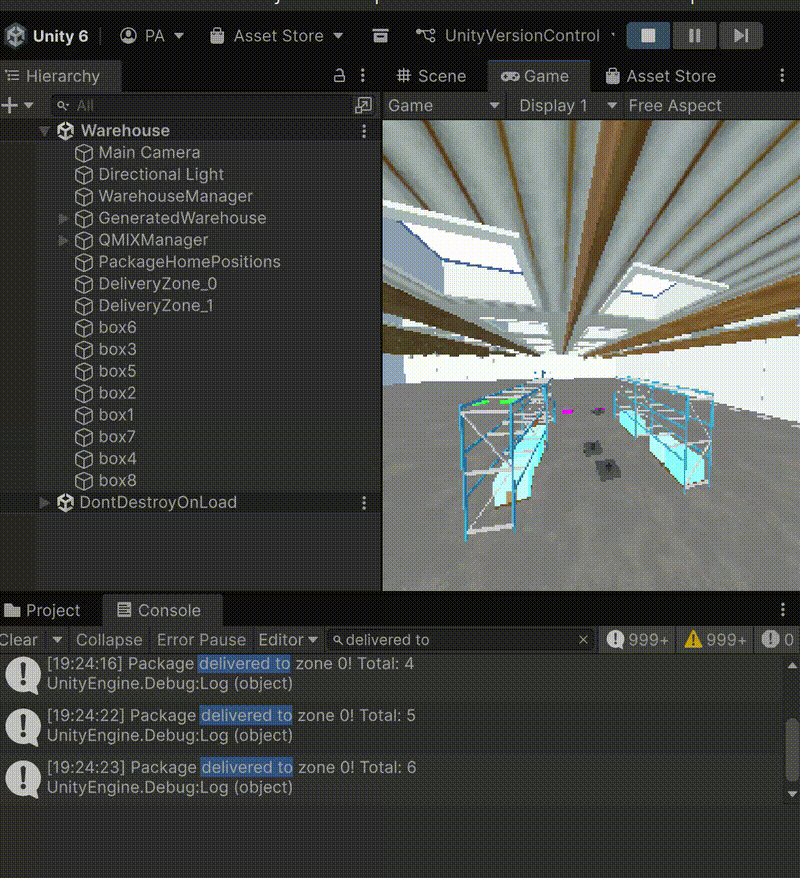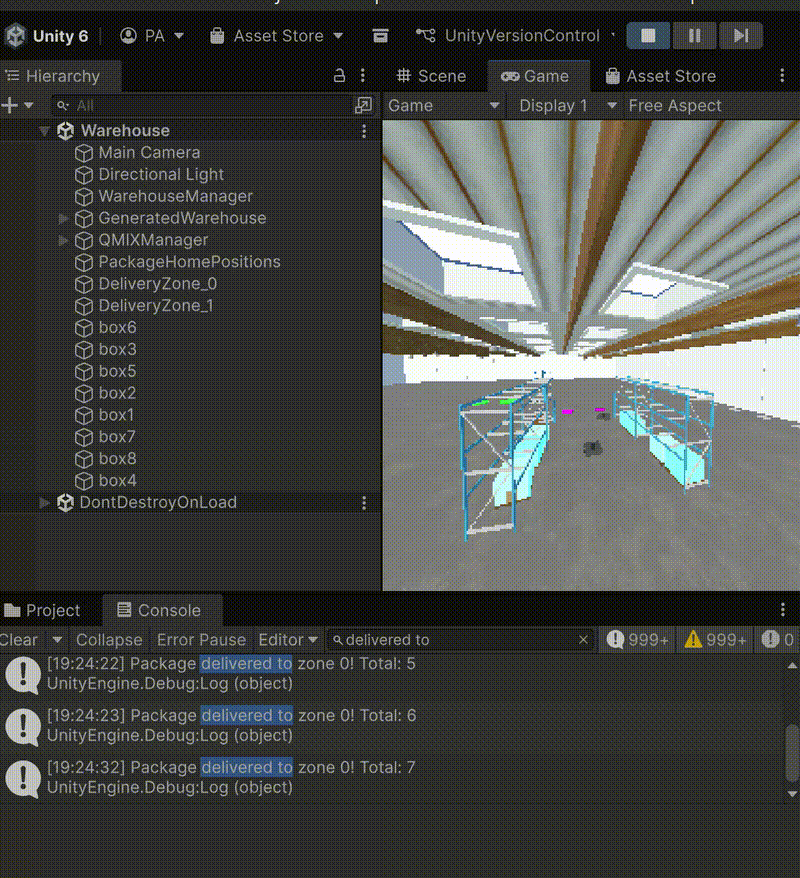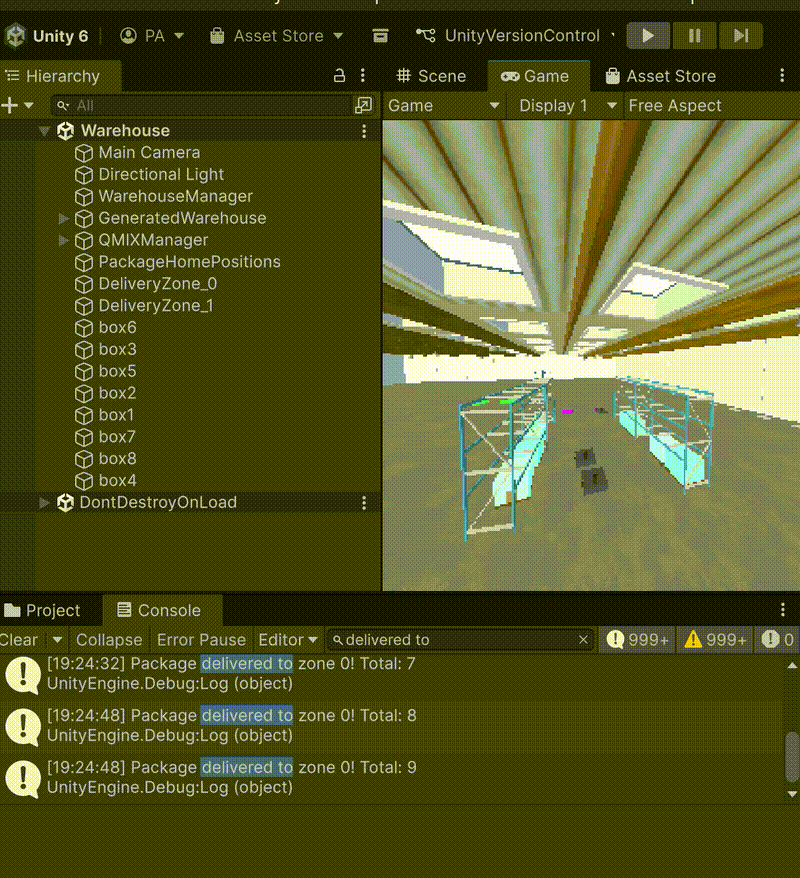
Figure 1: Agents operating with 10% exploration (ε=0.1). Agents successfully pick and deliver packages when random exploration is enabled.
17.4 3. Critical Discovery - Learning Failure Analysis
17.4.1 3.1 The Problem
Despite achieving high training returns (207.96), agents exhibited near-zero performance when evaluated with a pure greedy policy (ε=0.0). This indicated a fundamental learning failure.
17.4.2 3.2 Hypothesis Testing
Hypothesis: Agents rely entirely on random exploration rather than learned Q-values.
Test: Compare performance with different epsilon values during evaluation.
| Configuration | Test Return | Interpretation |
|---|---|---|
| Training (ε: 1.0→0.1) | 207.96 | Baseline with exploration |
| Evaluation ε=0.0 (pure greedy) | 0.21 | Learned Q-values produce no useful behavior |
| Evaluation ε=0.1 (10% random) | 191.22 - 253.52 | Random actions restore performance |
17.4.3 3.3 Key Finding
Adding just 10% random exploration during evaluation resulted in a 904-1207× improvement over pure greedy evaluation.
This proves:
- The Q-network’s learned values don’t encode useful warehouse task behavior
- All task performance comes from randomly stumbling upon packages and goals
- Agents never learned coordinated pick-and-place strategies
- High training returns were misleading - they came from exploration, not learning
17.4.4 3.4 What Successful Learning Would Look Like
If agents had learned properly, we would expect:
- Pure greedy (ε=0.0) performance to match or exceed ε=0.1 performance
- Only a small gap between training and test returns
- Improving performance as epsilon decreases during training
Instead, performance collapses completely without randomness, confirming the Q-network learned nothing meaningful after 350k training steps.
17.5 4. Root Cause Analysis
17.5.1 4.1 Identified Issues
- Sparse Rewards: Current reward structure may not provide sufficient learning signal
- Delivery reward: +1.0 (rare)
- Pickup reward: +0.5 (occasional)
- Small step rewards: +0.01-0.05 (frequent but tiny)
- Observation Space: Agents may lack critical environmental information
- Limited sensor range
- No global state information
- Partial observability makes coordination difficult
- Training Duration: Only 350k/500k steps completed
- Unity Editor timeout at ~3.5 hours
- Hardware constraints (CPU-only, 8GB RAM)
- May need 1M+ steps for meaningful learning
- Exploration Schedule: Epsilon anneals to 0.1 by 200k steps
- May reach greedy policy too quickly
- Insufficient exploration of state space
17.6 5. Hardware Constraints & Limitations
17.6.1 5.1 Training Environment
- Hardware: Personal laptop (CPU-only training)
- Memory: 8GB RAM (limited batch sizes)
- Training Time: ~3.5 hours maximum before Unity timeout
- Steps Achieved: 350k/500k (70% of target)
17.6.2 5.2 Impact on Results
The hardware constraints significantly limited:
- Training duration: Could not complete full 500k steps
- Batch size: Limited to 16 (may need 32-128 for stability)
- Network capacity: Smaller networks to fit in memory
- Exploration: Insufficient time to explore state space thoroughly
Conclusion: Personal hardware is insufficient for meaningful MARL research. Cloud computing resources (GPU-enabled) are necessary for:
- Longer training runs (1M+ steps)
- Larger batch sizes
- Deeper networks
- Multiple parallel environments
17.7 6. Lessons Learned
17.7.1 6.1 Technical Insights
- Training returns can be misleading: High returns during training don’t guarantee learned policies
- Always test with ε=0.0: Pure greedy evaluation reveals true learned performance
- Exploration vs. exploitation: Our agents became “exploration addicts” - unable to function without randomness
- Hardware matters: MARL research requires significant computational resources
17.7.2 6.2 Debugging Methodology
The systematic approach to diagnosing the learning failure:
- Observe anomaly: Agents don’t move during greedy evaluation
- Form hypothesis: Performance relies on exploration, not learning
- Design test: Compare ε=0.0 vs. ε=0.1 evaluation
- Analyze results: 904-1207× improvement confirms hypothesis
- Investigate root causes: Sparse rewards, limited observations, insufficient training
This methodology proved crucial for understanding the true nature of the learning failure.
17.8 7. Recommendations for Future Work
17.8.1 7.1 Immediate Next Steps
- Cloud Computing: Migrate to GPU-enabled cloud platform (AWS, Google Cloud, or Azure)
- Target: 1-2M training steps
- Use multiple parallel environments
- Enable larger batch sizes (64-128)
- Reward Shaping: Redesign reward structure
- Add intermediate rewards for approaching packages/goals
- Reduce reliance on sparse delivery rewards
- Implement curiosity-driven rewards
- Observation Space Enhancement
- Increase sensor range
- Add communication channels between agents
- Provide partial global state information
- Curriculum Learning: Start with simpler tasks
- Single agent pickup/delivery
- Two agents coordination
- Gradually increase to full multi-agent scenario
17.8.2 7.2 Algorithm Improvements
- Exploration Strategy
- Slower epsilon annealing (400k-500k steps)
- Use ε-greedy with minimum exploration (ε_min=0.05)
- Consider curiosity-driven exploration (ICM, RND)
- Network Architecture
- Increase hidden dimensions (64→128)
- Add attention mechanisms for agent coordination
- Experiment with transformer-based architectures
- Training Stability
- Implement gradient clipping more aggressively
- Use learning rate scheduling
- Add batch normalization or layer normalization
17.8.3 7.3 Evaluation Protocol
- Always include both:
- Training with exploration (ε=0.05-0.1)
- Pure greedy evaluation (ε=0.0)
- Track multiple metrics:
- Episode return
- Task completion rate (packages delivered)
- Collision rate
- Agent coordination efficiency
- Visualize behavior regularly:
- Record videos at checkpoints
- Inspect learned Q-values
- Analyze action distributions
17.9 8. Conclusion
This project successfully implemented QMIX for warehouse robots but revealed a critical learning failure: agents rely entirely on random exploration rather than learned policies. The systematic investigation using controlled experiments (comparing ε=0.0 vs. ε=0.1) proved invaluable for diagnosing the issue.
Key Takeaways:
- Hardware constraints are real: Personal computers are insufficient for serious MARL research
- Evaluation methodology matters: Always test with pure greedy policies to reveal true learning
- High training returns ≠ successful learning: Exploration can mask learning failures
- Systematic debugging pays off: Hypothesis-driven testing revealed the root cause
Moving forward, cloud computing resources, improved reward shaping, and longer training runs are essential for achieving meaningful learning in this challenging multi-agent coordination task.
17.10 9. Appendix - Training Logs
17.10.1 9.1 Run #93 Configuration Summary
{
"name": "qmix",
"env": "unity_warehouse",
"seed": 206687778,
"t_max": 500000,
"batch_size": 16,
"buffer_size": 5000,
"lr": 0.001,
"epsilon_start": 1.0,
"epsilon_finish": 0.1,
"epsilon_anneal_time": 200000,
"test_interval": 20000,
"save_model_interval": 100000
}17.10.2 9.2 Evaluation Results
Greedy Evaluation (ε=0.0):
test_return_mean: 0.21
test_return_std: 0.45
test_episode_length: 199.9 stepsExploration Evaluation (ε=0.1):
Run #97:
test_return_mean: 191.22
test_return_std: 111.56
Run #98:
test_return_mean: 253.52
test_return_std: 98.92Performance Improvement: 904-1207× when adding 10% exploration
17.10.3 9.3 GitHub Repository
Full code, documentation, and training checkpoints available at: https://github.com/pallman14/MARL-QMIX-Warehouse-Robots