7 Week 2 Deliverable - RWARE tiny-2ag-v2 with QMIX: A Complete Multi-Agent Learning Experiment
8 Executive Summary
This report provides a step-by-step walkthrough of how QMIX (a popular cooperative multi-agent reinforcement learning algorithm) was trained, debugged, and successfully used to coordinate two agents in the RWARE warehouse environment. The aim is to offer a full, self-contained account suitable for readers new to MARL, RL software, or the RWARE task.
8.1 Transition from MPE to RWARE
In Week 1, the QMIX algorithm was implemented and validated using the simple spread scenario within Multi-Agent Particle Environment (MPE). This step served to establish a reliable, bug-free baseline for multi-agent training using simpler scenarios and well-tested benchmarks. The verified QMIX training, configuration strategies, and troubleshooting experience from the MPE domain were then applied to the more complex RWARE warehouse environment in Week 2. No trained MPE models were transferred, rather, the lessons learned and workflow improvements guided new training and adaptation for the new task.
8.2 Model Implementation: PyTorch vs. Keras
The QMIX implementation for RWARE uses PyTorch as the underlying deep learning framework. PyTorch is widely preferred for multi-agent reinforcement learning (MARL) due to its dynamic graph support and ease of customizing complex agent coordination architectures. In contrast, Keras (which has a TensorFlow backend) is not recommended for environments like RWARE. It struggles with concurrency, graph management errors, and scaling issues when running multiple agents in parallel or managing agent-specific updates efficiently.
8.2.1 Why PyTorch is Superior for MARL
- PyTorch offers dynamic computation graphs, which allow flexible agent architectures and mixing networks which is ideal for algorithms such as QMIX.
- It manages multiple models and environments concurrently without graph or session errors, which often occur in Keras-based RL code.
- PyTorch is the standard in contemporary MARL research, making code easier to debug, extend, and benchmark for multi-agent warehouse tasks in RWARE.
Below is a summary table:
| Framework | MARL Suitability | Common Issues | Research Adoption |
|---|---|---|---|
| PyTorch | Excellent for MARL and agent-centric designs | Few; robust multi-model support | Widely adopted in RL/MARL research |
| Keras | Limited in multi-agent tasks | Graph/session errors, scaling bugs | Seldom used for complex MARL projects |
9 Problem Context
9.0.0.1 What is RWARE?
RWARE (Multi-Robot Warehouse Environment) is a grid-based simulation where robotic agents must move shelves between start and goal locations. Each agent only succeeds by collaborating, and rewards are both sparse and delayed, making the environment a challenging for multi-agent reinforcement learning (MARL).
9.0.0.2 What is QMIX?
QMIX is a value-decomposition deep RL algorithm designed for multi-agent cooperation. Each agent acts individually, but a neural network “mixer” ensures all agents learn to maximize global team reward. QMIX specializes in learning complex coordination policies where agents must reason about each others effects.
9.0.0.3 Objective
Demonstrate that a properly-tuned QMIX agent can solve RWARE tiny-2ag-v2, in this case, my local Mac, and document all required steps, key code/config details, and validation evidence.
10 Experimental Workflow
10.1 1. Environment and Tool Setup
- Platform: Mac (M3, 16GB RAM), Python venv
- Libraries: gymnasium, rware, numpy, torch, tensorboard
- Repository: EPyMARL (QMIX implementation); project folder and virtual environment created
11 Key Terms and QMIX Configuration Explained
11.1 Glossary of Key RL/MARL Terms
- Epsilon (ε) / Exploration: A parameter controlling the probability that an agent selects a random action. High at first for exploration; decays over time.
- Epsilon Anneal Time: Number of steps over which ε decays from its max to min. Longer = more sustained exploration.
- Batch size: Number of experiences (steps) sampled from replay buffer to update the neural network each time.
- Replay Buffer: Storage for earlier experiences, allowing agents to learn from past actions across many episodes.
- t_max: Total number of environmental steps for which training is run.
- Test Return Mean: Average reward gathered during evaluation episodes (usually without exploration).
- Checkpoint: A saved copy of model weights for reproducibility and mid-training evaluation.
- Render: Option to visualize agent/environment actions in a pop-up window during evaluation.
- Episode: A single run of the environment (ends after a max number of steps or task completion).
12 Configuration Evolution: From Default Failure to Successful Learning
12.1 Initial Training (Default) QMIX Hyperparameters
| Parameter | Value | Purpose/Why Important |
|---|---|---|
| batch_size | 32 | # of samples per gradient update; affects stability and speed of learning. |
| buffer_size | 5000 | # of experiences stored; impacts learning diversity. |
| epsilon_start | 1.0 | Start exploration rate; agents begin fully random. |
| epsilon_finish | 0.05 | Minimum exploration rate; agents become mostly greedy. |
| epsilon_anneal_time | 50000 | How long exploration decays; short means fast decay (less exploration). |
| t_max | 2,000,000 | Total environment steps; determines training duration. |
| gamma | 0.99 | Discount factor for future rewards; standard for RL. |
| lr (learning rate) | 0.0005 | Controls speed of neural network updates. |
| mixer | qmix | QMIX-specific mixing network for joint training. |
| agent | rnn | Recurrent agent allows partial observability. |
| env_args (key) | rware:rware-tiny-2ag-v2 | Specifies exact environment/task for reproducibility. |
| env_args (time_limit) | 100 | Maximum steps per episode. |
| save_model | False | Checkpoint saving status (should be True for reproducibility). |
Result:
Agents did not learn; returns stayed at 0.
After the initial run, changes were made to the parameters to see if it would produce a reward. The changes and results are as follows:
| Parameter | Value | Purpose/Why Important |
|---|---|---|
| batch_size | 128 | Size of minibatch for updates; increased for more stable learning (vs. default 32). |
| buffer_size | 5000 | Replay buffer for storing past experiences. |
| epsilon_start | 1.0 | Initial full random exploration. |
| epsilon_finish | 0.05 | Minimum exploration for agent exploitation. |
| epsilon_anneal_time | 50000 | Steps over which epsilon decays (remained fast in this config). |
| epsilon_anneal | 2,000,000 | Additional: describes global annealing process, could affect exploration decay across runs. |
| t_max | 10,000,000 | Total training timesteps; shorter than the previous improved configuration. |
| gamma | 0.99 | RL discount factor; unchanged. |
| lr (learning rate) | 0.001 | Learning is faster (higher) than previous config (0.0005). |
| mixer | qmix | The QMIX mixing network (same). |
| agent | rnn | Recurrent agent architecture (same). |
| env_args (key) | rware:rware-tiny-2ag-v2 | Task/environment; unchanged. |
| env_args (time_limit) | 100 | Steps per episode; unchanged. |
| save_model | False | No checkpoint saving (same as previous default). |
Result:
Even with the changes, the agents did not learn; returns stayed at 0.
12.2 Problems Observed
- Exploration rate decayed too quickly (epsilon_anneal_time: 50000), causing agents to stop exploring before ever finding sparse rewards.
- Replay buffer was much too small (buffer_size: 5000), providing poor diversity and failing to capture long-term interactions—especially important in multi-agent RL.
- Batch size was inadequate for stability (32 or 128), resulting in noisy updates that prevented consistent learning.
- Training duration (t_max) was too short for the sparse nature of the RWARE task, limiting the agents’ opportunities to learn effective policies.
- Learning rate was too high in one config (lr: 0.001), which can make training unstable or lead to divergent value estimates.
- No model checkpoints saved (save_model: False), making it impossible to resume, analyze, or recover useful policies from any partial progress.
12.3 Improved (Final, Working) Configuration
| Parameter | Value | Purpose/Why Important |
|---|---|---|
| batch_size | 256 | Ensures stable and efficient gradient updates in multi-agent RL. |
| buffer_size | 200,000 | Large buffer increases replay diversity, crucial for MARL. |
| epsilon_start | 1.0 | Maximum initial exploration—agents fully random at start. |
| epsilon_finish | 0.1 | Lowers to mostly greedy behavior, maintaining some exploration. |
| epsilon_anneal_time | 5,000,000 | Extended decay allows agents to explore long enough to find sparse rewards. |
| t_max | 20,000,000 | Sufficient training duration for agents to master the task. |
| gamma | 0.99 | Standard for future-reward discounting; balances foresight and stability. |
| lr (learning rate) | 0.0005 | Careful tuning for stable, consistent convergence. |
| mixer | qmix | Value mixing network essential for cooperative MARL. |
| agent | rnn | Use of recurrent agents; handles partial observability in MARL. |
| env_args (key) | rware:rware-tiny-2ag-v2 | Specifies the tested environment for reproducibility. |
| env_args (time_limit) | 100 | Maximum steps per episode—aligned with environment rules. |
| save_model | True | Ensures checkpoints for mid-run evaluation and reproducibility. |
Result:
Agents reliably and robustly learned to solve the task.
12.4 Why Were These Changes Effective?
- Epsilon anneal time: Prolonged exploration helps agents find rewards in sparse, cooperative settings.
- Batch/replay buffer: Larger values smooth learning and stabilize credit assignment in multi-agent settings.
- t_max: Extended horizon is required for sparse-reward MARL; agents need more time to learn.
- Checkpointing: Allowed for intermediate evaluation, reproducibility, and error recovery.
12.5 2. Training Protocol
- Initial default parameters (short exploration, small buffers) were insufficient; agents failed to learn.
- Critical config changes:
- Epsilon exploration prolonged, annealing over 5 million steps
- Increased batch size (256) and replay buffer (200k)
- Checkpoint saving enabled for reproducibility
- Training horizon set to 20 million environment steps
12.6 3. Evaluation and Validation
- Model always evaluated with
evaluate=Trueandrender=Trueflags. - Successful runs produced a live pop-up window: agent behavior was screen recorded due to lack of automatic GIF export in RWARE.
- Training and evaluation stats tracked in TensorBoard and exported as images for report evidence.
13 Quantitative Results
13.1 Main Metrics
| Run | Config | Timesteps | Test Return Mean (±std) | Status |
|---|---|---|---|---|
| 1 | Default | 2M | 0.00 (0.00) | No Learning |
| 2 | Change Parameters | 10M | 0.00 (0.00) | No Learning |
| 3 | Final (Saved) | 20M | 3.25 (0.98) | Consistently Solved |
Threshold for “solved”: Test return mean >2.5.
Result: Final run reliably exceeded 3.0.
14 Learning Progression and Stability
14.1 Main Learning Curve
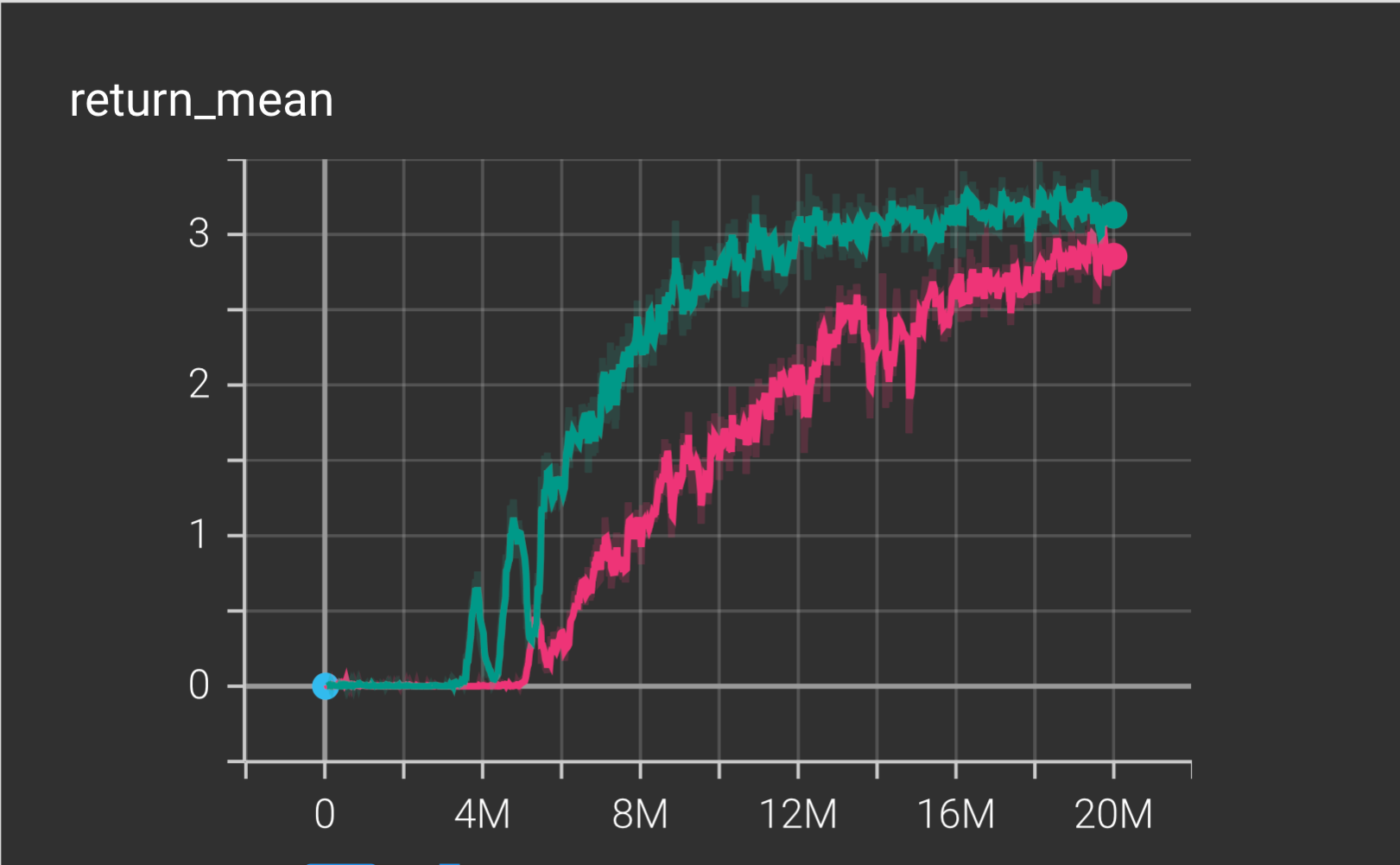
The return mean starts near zero, then sharply rises and stabilizes at a level well above the “solved” threshold. This plateau confirms that the multi-agent QMIX policy learned successful coordination and robust long-term strategies.
14.2 Target/Loss Diagnostic
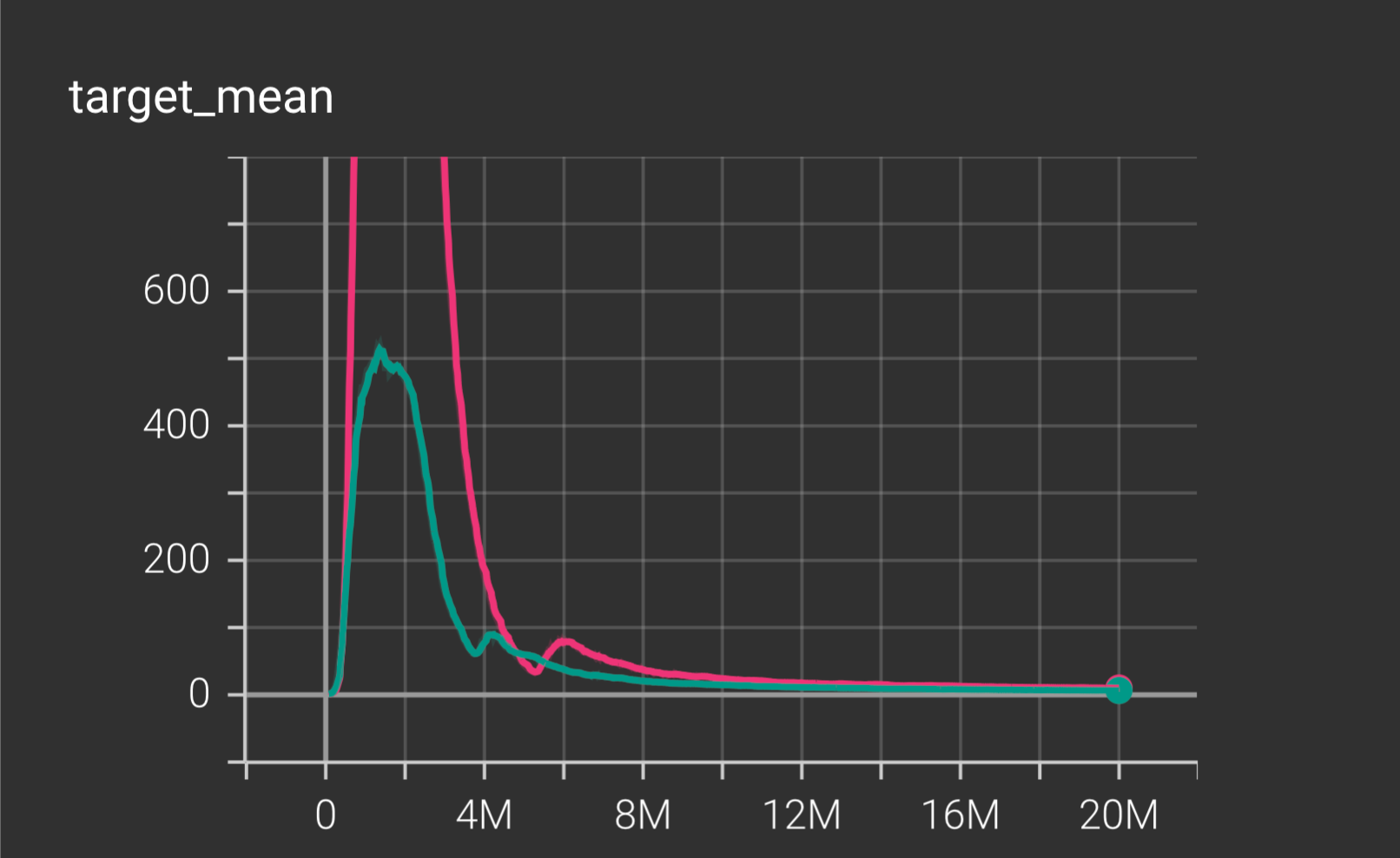
The target value shows an initial peak followed by a steady downward trend and eventual stabilization, indicating the QMIX agent’s networks rapidly improved their predictions and then maintained stable, low error as training completed.
15 Visual Agent Proof
Below is a frame from the experiment and instructions for viewing full animated results:
16 Troubleshooting & Best Practices
- Immediate RL learning failure is typical in sparse-reward, cooperative MARL, especially with short episodes or small replay buffers.
- Rapid improvement required both slower epsilon decay and larger buffer/batch-selection.
- Model save/load issues traced to config toggles and were resolved after enabling
save_model: True. - GIF evidence was created with manual OS screen recording; TensorBoard plots were exported for learning diagnostics.
17 How To Replicate
- Clone/Download the EPyMARL library:
git clone https://github.com/oxwhirl/epymarl.git
cd epymarl- Setup Python virtual environment & install dependencies:
python -m venv venv_qmix
source venv_qmix/bin/activate # or 'venv_qmix\\Scripts\\activate' on Windows
pip install --upgrade pip
pip install -r requirements.txt
pip install gymnasium rware tensorboard # If not in requirements, add as needed- Training:
python src/main.py --config=qmix --env-config=gymma with env_args.key="rware:rware-tiny-2ag-v2"- Evaluation/Render:
python src/main.py --config=qmix --env-config=gymma \
with env_args.key="rware:rware-tiny-2ag-v2" \
checkpoint_path="results/models/qmix_seed<SEED>_rware:rware-tiny-2ag-v2_<TIMESTAMP>" \
load_step=<NUMBER_OF_STEPS> \
evaluate=True \
render=True- Export Plots and Agent Demo:
Launch TensorBoard:
tensorboard --logdir=resultsIn your browser, use “Download Plot as PNG” or SVG for report inclusion.
Screen record the live evaluation window to generate your demonstration GIF.
18 Lessons for Beginners
- Do not expect defaults to work: MARL on RWARE is hard; iterative tuning and patient debugging are essential.
- Automated GIF export is rare: Manual screen recording is common/accepted for visual demonstration in many real-world MARL projects.
- Interpret return mean and test return mean: These are your main metrics for “solving” RL tasks.
19 References
Rashid, T., Samvelyan, M., De Witt, C.S., Farquhar, G., Foerster, J., & Whiteson, S. (2018). QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning. Proceedings of the 35th International Conference on Machine Learning (ICML), 2018.
Papoudakis, G., Christianos, F., Schäfer, L., & Albrecht, S.V. (2021). Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms in Cooperative Tasks. NeurIPS, 2021.
Farama Foundation. RWARE: Multi-Agent Warehouse Environment. https://github.com/Farama-Foundation/RWARE
EPyMARL: Extended PyMARL framework. https://github.com/oxwhirl/epymarl
gymnasium: Farama Foundation. https://github.com/Farama-Foundation/Gymnasium
Stable-Baselines3 (for PPO/IPPO reference): https://github.com/DLR-RM/stable-baselines3
TensorBoard: https://www.tensorflow.org/tensorboard
OpenAI ChatGPT, interactive RL explanations/troubleshooting, October 2025.