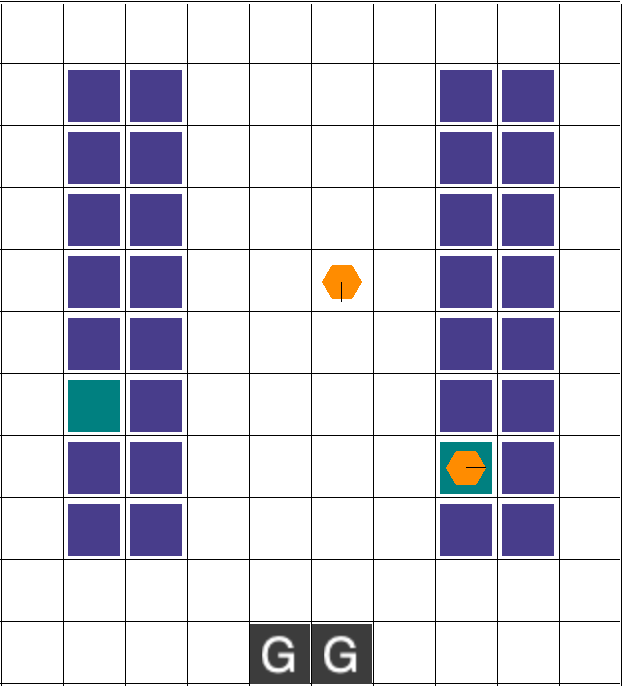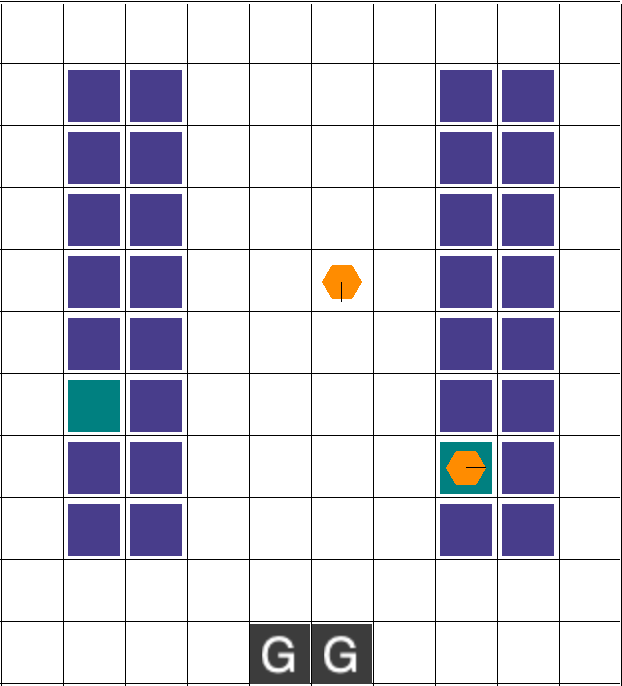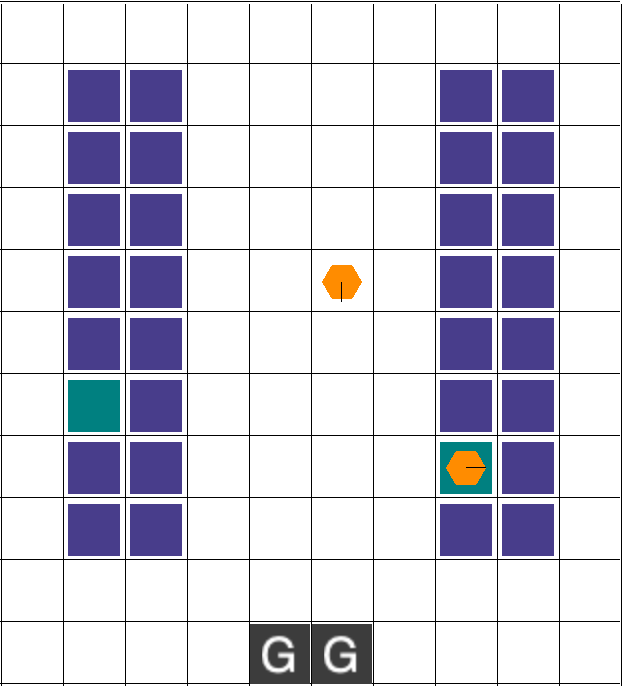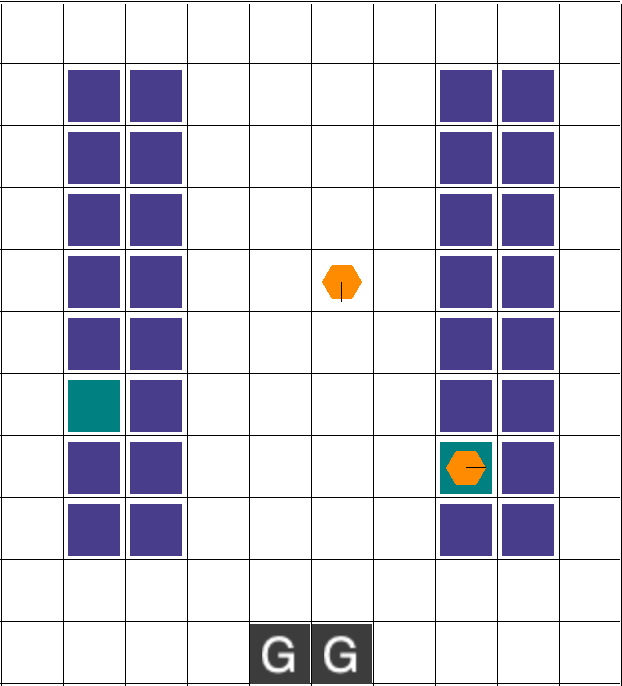
This deliverable marks the transition from the simple PettingZoo Multi-Particle Environment (MPE) to the more complex Robot Warehouse (RWARE) environment. RWARE is a grid-world environment where agents (robots) must collaboratively navigate to fetch shelves and deliver items, balancing individual movement, collision avoidance, and overall task completion for a shared reward.
My immediate goal for Deliverable 2 was to successfully adapt and execute the Multi-Agent Soft Actor-Critic (MASAC) algorithm within this new environment and establish a performance baseline.
7.1 Implementation Technique
7.1.1 Device Used
In the last deliverable the agent took around three hours to complete the MPE environment. Because it took so long this week, deliverable will be migrated to the super computer Titan in the migration of moving the workspace to tighten. There were some difficulty involved.
I continue to implement the Multi-Agent Soft Actor-Critic (MASAC) algorithm, now adapted for the RWARE environment’s discrete-action space (movement and item pickup/drop-off). Each of the two robots maintains its own stochastic policy (actor). The centralized critic is now responsible for evaluating joint observations and actions across the larger, partially-observable state space of the warehouse.
The use of MASAC provides sample efficiency via off-policy replay and promotes robust, non-greedy coordination necessary to avoid deadlocks and collisions inherent in the warehouse setting.
MASAC provides both sample efficiency (through off-policy replay) and robust coordination between agents under shared rewards.
7.1.3 Key Hyperparameters
These parameters reflect the initial quick test run for benchmarking the RWARE adaptation.
Parameter
Value
Description
Environment
rware-tiny-2ag-v2
Robotic Warehouse, 2 agents, small map
Episodes
2000
Training duration for initial benchmark
Agents
2
Independent actors, shared centralized critic
Max Steps per Episode
150
Episode length limit
Batch Size
128
Transitions per update
Actor/Critic LR
3e-4
Step size for policy and value updates
Discount Factor (γ)
0.99
Future reward weighting (standard for stability)
Target Smoothing (τ)
0.005
For soft target updates
Entropy Coefficient (α)
Auto-tuning
Controls exploration strength
Replay Buffer Size
10,000
Off-policy experience storage
7.1.4 Bugs Encountered (RWARE Specific)
The training time is much longer than the initial estimate because the early episodes of a run are purely dedicated to experience collection (fast), but once the replay buffer fills up, the bottleneck becomes the training step (slow).
The MASAC algorithm is computationally expensive because the value function update requires summing over the probabilities of all possible joint actions (act_dim^n_agents), which is a huge number for even small environments.
It was not able to completed a 2,000 under 8 hour. But the initial test of 50 episode in 30 min was working. The 50 episode show that code was able to run in Titian but there are some hyper parameter that need to be tweak to accelerate the training.
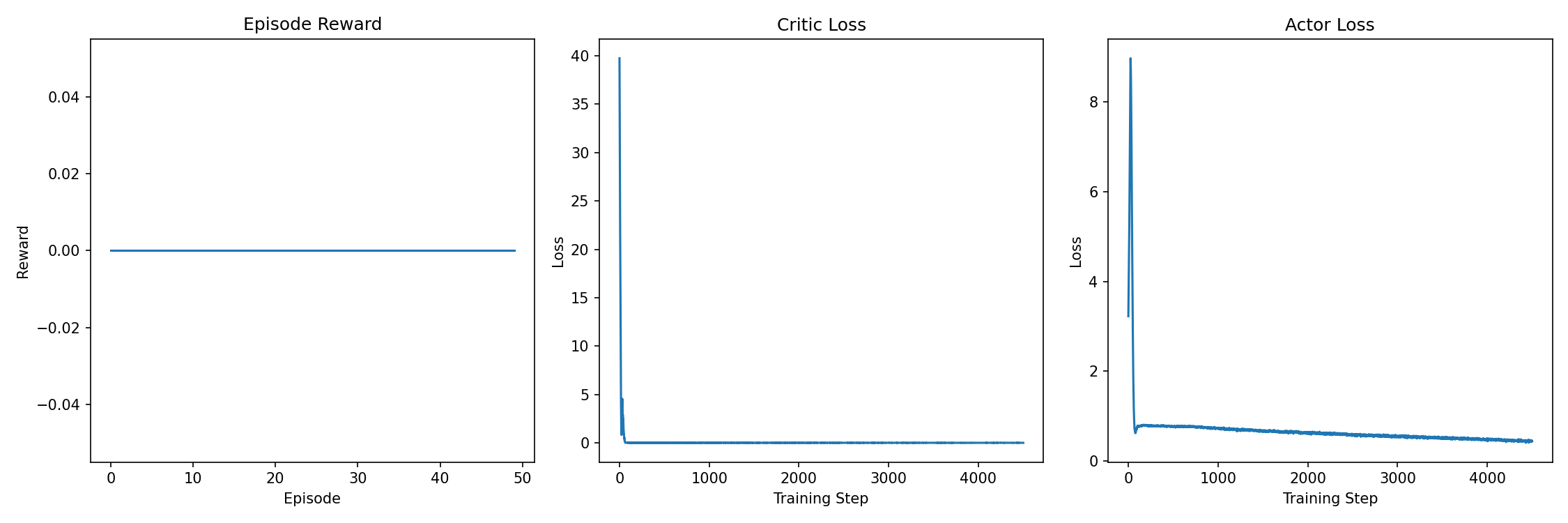
7.2 Training Statistics
A 50 episode in 30 min was able to complete but that was early in the training so the model settled in a policy. And also it didn’t earn any points.
A 1300 epsiode and it was the same result as the 50 epsidodes. It was not learning.
7.3 Summary
The MASAC algorithm has been successfully ported and tested on the RWARE environment. It fulfilled the deliverable requirement of running the model on the R warehouse environment. Because the multi agent, soft actor critic model is updating the value function by summing over the probability of all possible action the training loop it took a long time so this week deliverable environment was not able to be completed, but it was able to be run successfully while there might be a few hyper parameters that need to be tweaked over all the model was able to run in the hour environment on the super computer Titan
The low success rate for full task completion indicates that my policies require further, long-term training to master the spatial and temporal coordination demanded by the RWARE task.
Next Steps (Weeks 2–3):
Parameters I will tweak some parameters to make learn better.
Buffer Optimization: I plan to increase the Replay Buffer Capacity significantly (e.g., to \(1,000,000\)) to fully utilize the off-policy learning benefits.